
Individual Pricing Estimates
Individualized insurance patient cost estimates via a combination of machine learning and manual curation.
Counsyl’s mission to make genomics useful and accessible to everyone includes making it affordable and understandable. To ensure our patients have a transparent understanding of the cost our test, we prepare an individual pricing estimate for each patient based on their unique insurance benefits.
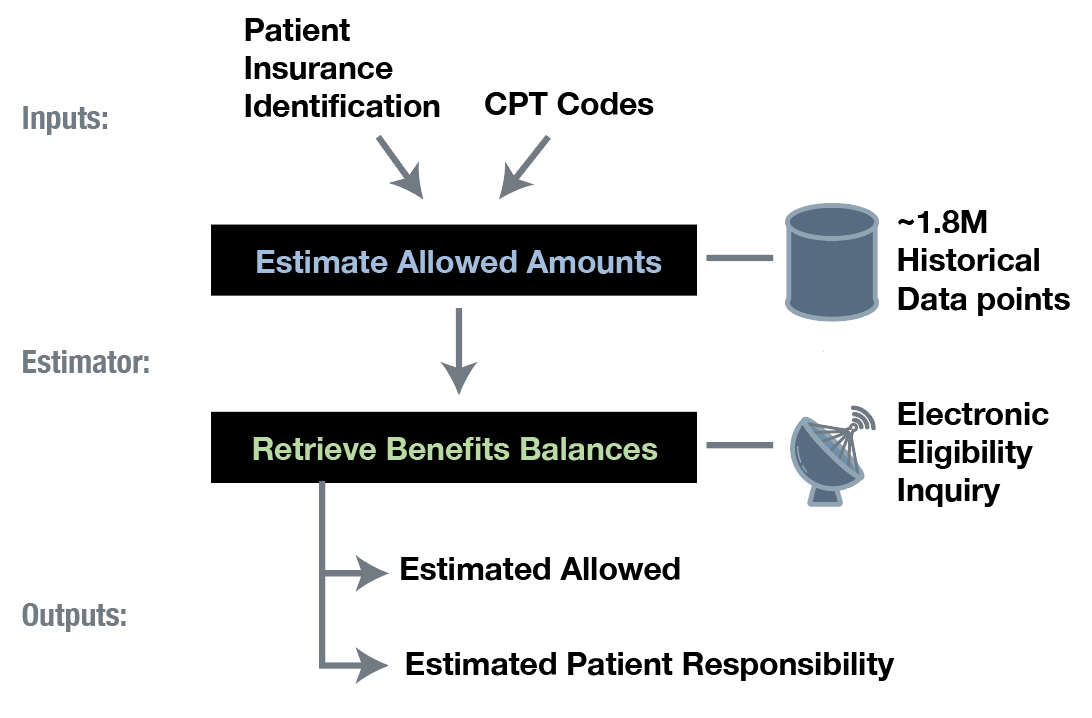
There are two essential parts to preparing an insurance estimate: determining patient benefits and estimating allowed charges. First, a third-party clearinghouse is used to retrieve benefits from the hundreds of insurers that cover our patients. A series of manually-curated filters, maintained using an A/B comparison tool, are used to select the coverage information that applies to Counsyl’s genetic tests from among the many values returned by the insurer.
Next, a hand-tuned decision tree is used to determine what the insurer is like to pay (“allow”) for our services. We use more than 1.8 M historical claim datapoints to make an estimate of expected payment. A prediction pipeline continuously trains the system as insurers respond to our claims.
Finally, the benefits and allowed estimates are combined in a clear and simple web page that presents the cost estimate and helps patients understand their payment options. Patients receive notification of their estimates via email and SMS within a few minutes of order placement.
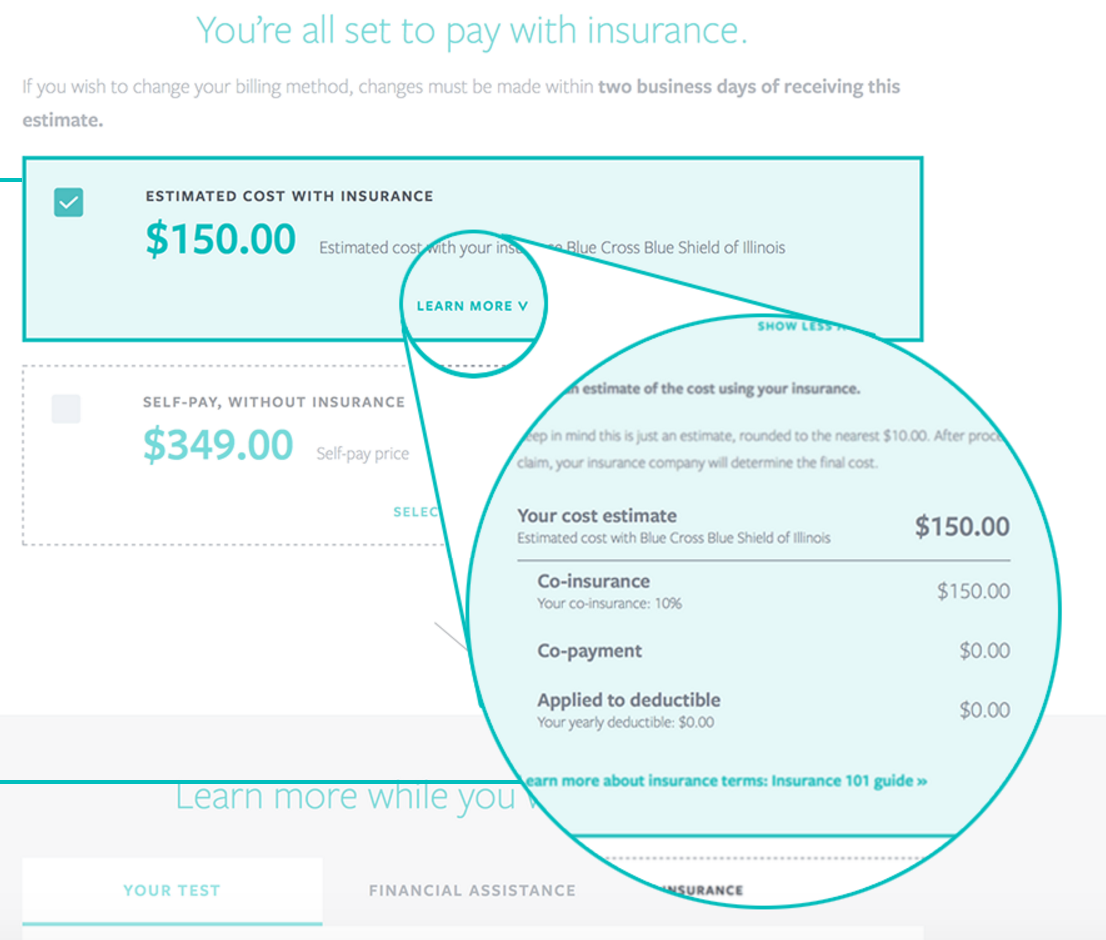
I was responsible for most of the architecture and backend work to prepare, store, and track accuracy of estimates. When I joined Counsyl, we had little understanding of just how difficult the project would be. I’ve spent about two and half years refining the system, at first individually, and then with a team of two to six engineers and designers. We’ve been able to achieve considerable accuracy improvements through a combination of targeted machine learning and manual curation.
For more detail, see a talk I gave about the system.